更新时间:2024-02-28
模型是深度学习的核心技术之一,我们平时在从事相关工作时,有很大一部分精力都在模型设计和优化上。对于新手朋友们来说,往往只会跑一跑别人的模型或者只会盲目的简单修改一下参数,不知道该如何进行设计和优化,如何系统性学习呢?
最重要地是,应该是针对数据存在的特点,设计专门的深度学习网络结构。
例如,有些信号非常干净,几乎不包含任何噪声信息;有些信号就特别嘈杂,受到了非常强烈的噪声干扰。
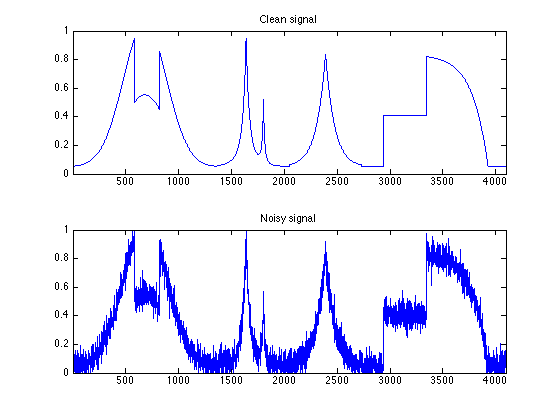
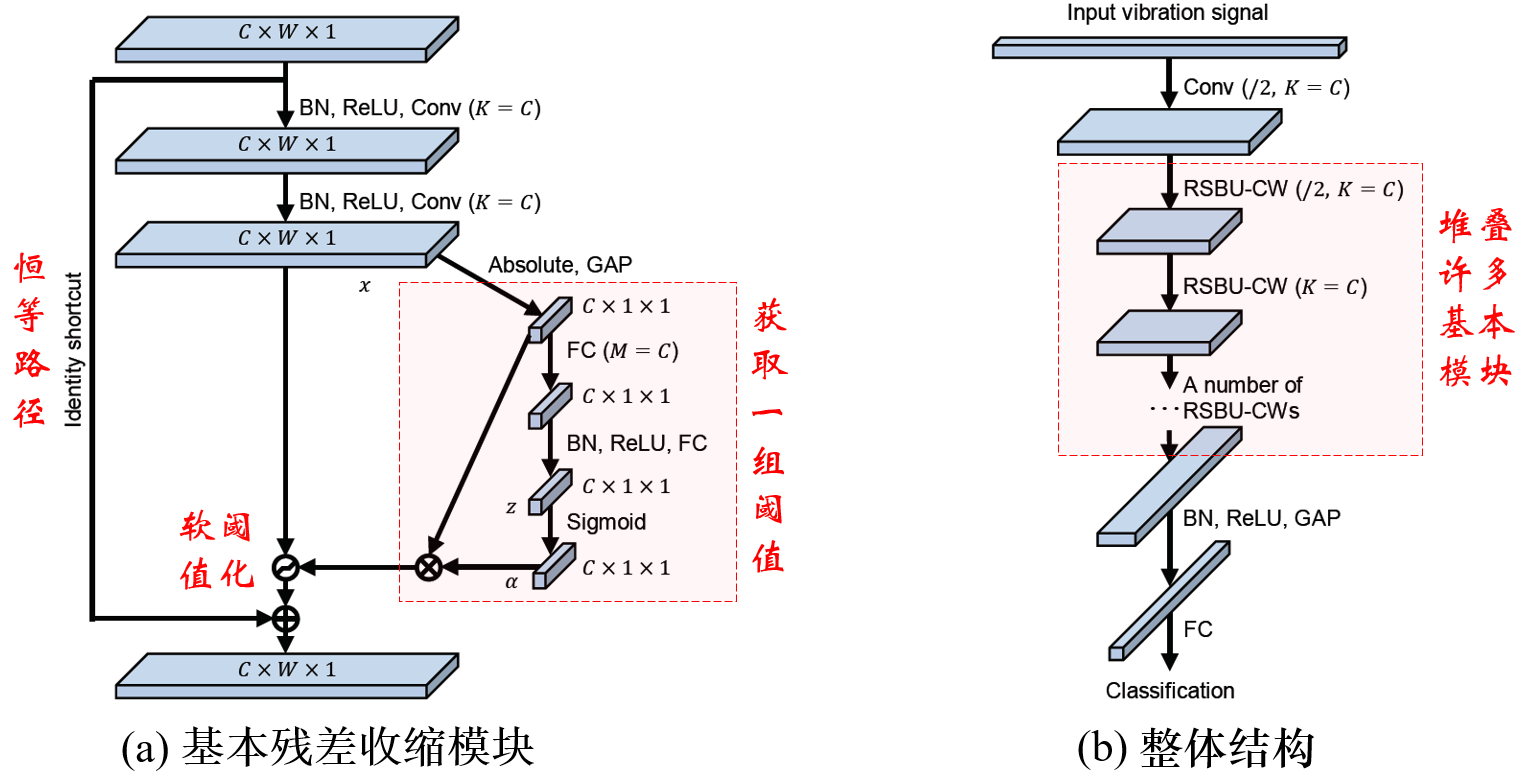
此时,如果数据中含有大量噪声,可以借鉴残差收缩网络[1][2],在深度学习网络模型中加入软阈值化。
深度学习入门基础,优化
这篇博文出自 MATLAB 产品经理 Heather Gorr。你可以在社交媒体上关注她:@heather.codes, @heather.codes, @HeatherGorr,以及 @heather-gorr-phd。这篇博文是在 YouTube 上精彩的建模竞赛现场直播之后发布的,MATLAB 的最佳模型:深度学习基础 指导您如何选择最佳模型。对于深度学习模型,有多种方法可以评估什么是“最佳”模型。可能是 a) 比较不同的网络(问题 1)或 b)为特定网络找到正确的参数(问题 2)。如何有效、快速地进行实验管理?在 MATLAB 中使用低代码工具,Experiment Manager APP!
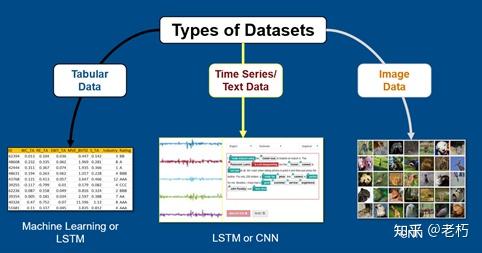
我们创建了两个问题:图像分类和时间序列回归。基于数据集,我们考虑了两种类型的模型:卷积 (CNN) 和长短期记忆 (LSTM) 网络。下图显示了用于不同数据类型的一些常见网络。
我们使用 MATLAB帮助文档中的示例来实现可重复性(以及用于直播的合理大小的数据集!)并使用 MATLAB 中的APP快速探索、训练和比较模型。当我们进入细节时,我们将讨论更多!
对于我们的第一个问题,我们比较了 CNN 模型来对花卉类型进行分类。CNNs很常见,因为它们涉及到一系列我们可以大致理解的操作:卷积、数学运算和聚合。

您可能还记得以前的帖子,我们在这个领域有一些很好的起点!我们使用了迁移学习,您可以在其中使用您的数据更新预训练网络。
我们首先使用 Deep Network Designer 探索预训练模型,该应用程序提供了对整体网络架构的了解,以帮助我们在深入细节之前进行选择。
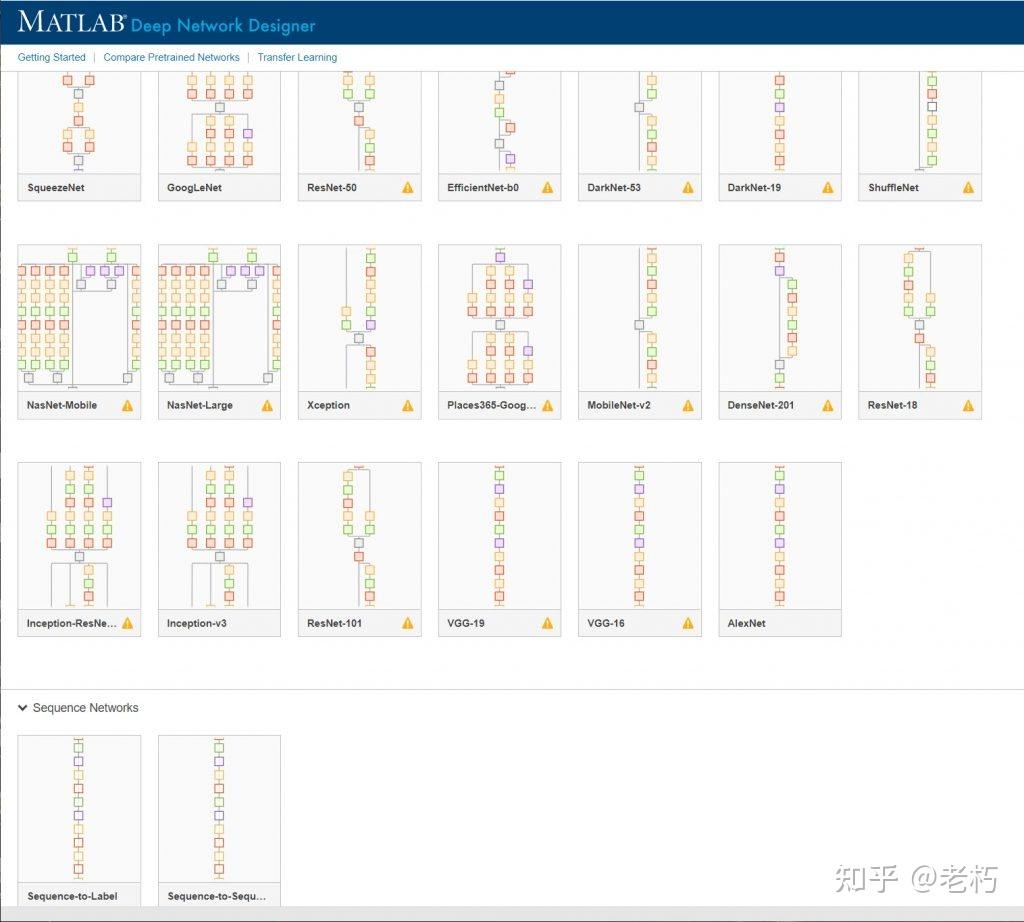
我们希望我们的比赛具有不同程度的复杂性,所以我们决定使用squeezenet、googlenet和inceptionv3。
接下来,我们需要训练和验证所有 3 个网络并比较结果!该Experiment Manager APP超级有助于我们组织和自动化这部分工作。
此帮助文档示例给出了如何设置和运行实验:
cd(setupExample('nnet/ExpMgrTransferLearningExample')); setupExpMgr('FlowerTransferLearningProject');
您可能知道,训练网络可能需要一些时间!在这里,我们正在训练其中的 3 个 - 因此您需要在开始运行之前考虑您的硬件和问题。您可以调整设置以使用 GPU 并通过APP轻松地将实验运行并行化。
我提前开始了实验,以确保我们有时间比较并在我的 Linux 机器上运行,我用了多 GPU来加速!
我们的模型表现如何?我们用来评估的几个标准:
针对这些评价的大多数措施都可以在APP中快速找到 —— 看图说话,因为它更加微妙!
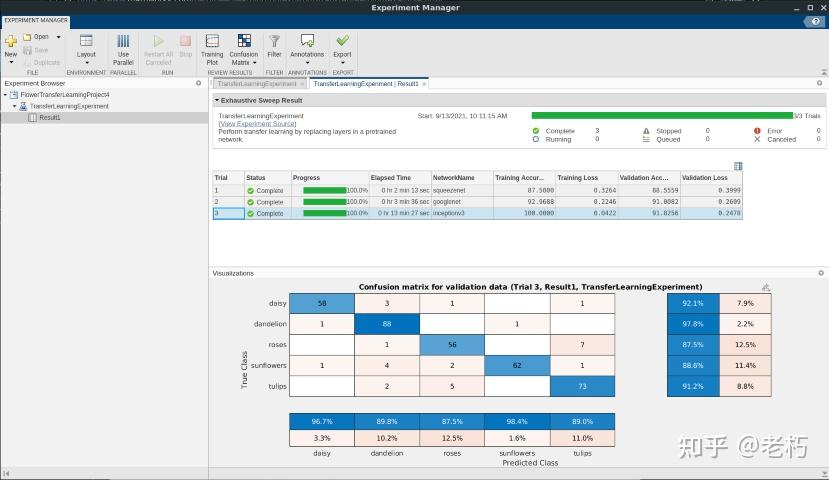
我们发现,在这个例子中,inceptionv3 获得了最佳 的准确度(91.9%),但也耗时最长,因为相较于其他模型它的架构更复杂些。看看亚军,googlenet 可能是一个更好的折衷方案,因为它速度更快,并且仍然具有类似的良好验证准确度 (91%)。Squeezenet 模型训练得最快,但准确度更差,尽管我不排除它!当涉及到最重要的问题时,每个问题都是不同的!最后,我们检查了看起来非常相似和平衡的混淆矩阵。这是一个非常重要的视觉效果,可帮助确保您要做的分类之间没有不平衡的准确度……这将我们引向我们的最后一个标准。
能够解释模型变得越来越重要,模型可解释性是 深度学习领域的一个活跃研究领域。我们将保持本节简短,因为关于这个方面我们将会推出更多的内容。基本上,您了解正在发生的事情,尤其是出现问题时(开发人员、团队,甚至用户都需要了解)。有一些很好的技术,例如网络激活和可视化,以及其他策略。
最后的一些提示 - 确保记录良好,如果您使用了预训练模型,请确保训练数据和模型信息透明且无偏见。
深度学习的很大一部分就是调整网络直到您对结果感到满意。为了改进层架构、求解器和数据表示,有许多参数需要调整。同样,APPs 将对此有所帮助,因为您可以在 Deep Network Designer 中轻松检查和调整参数,然后使用 Experiment Manager 执行参数扫描。
我们遵循了一个帮助文档示例,该示例显示了使用 googlenet 和一个简单的“默认”网络,尝试三个不同的求解器:
cd(setupExample('nnet/ExperimentManagerClassificationExample'));setupExpMgr('MerchandiseClassificationProject');我们不会在这篇文章中详细介绍可用的求解器,但是如果您忘记了带有动量的随机梯度下降 (sgdm) 和均方根传播 (RMSProp) 之间的区别,这是一个很好的探索方式!文档中有更多内容,包括对所有可调整参数的快速概览。
我们进行了实验并且 googlenet 在这里表现得更好(尽管显然需要更长的时间来训练)。有趣的是,比较求解器时准确度没有明显差异——更多数据可能有助于检查这一点。然而,求解器在具有最少层的默认算法中产生了很大的不同(70% vs 80%)。如果您看到这种变化,这是值得检查的情况类型!
接下来我们专注于时间序列回归问题。首先,让我们考虑一下整体架构。
CNN 对许多问题都有广泛的用处,但有时模型需要了解先前时间步长的信息。这就是递归神经网络 (RNN) 派上用场的地方,因为它们通过系统保留记忆,这使得它们非常适合时间序列、视频、文本和其他顺序问题。在深度学习术语中,CNN 是前馈,而 RNN 是后馈,它通过层的输入和输出携带一些记忆。
在这种情况下,我们专门研究了LSTM,它是一个 RNN,在输入和输出方面有额外的“门”。这有助于保留数据中的长期趋势,这对于时间序列问题很重要。下图比较了两个网络。
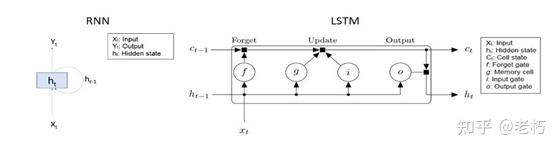
图 7:RNN(左)和 LSTM 网络(右)的比较
使用 LSTM,您通常不需要像 CNN 那样多的层 —— 艺术在于选择参数以最好地表示数据和趋势。虽然我遇到过非常深的 LSTM,但大多数情况下,网络只需很少的层就可以很好地学习。例如,Deep Network Designer 有一个包含 6 层的模板:input、lstm、dropout、fullyConnected、softmax 和一个分类或回归层。这是一个简单的架构,其中数据准备和层参数有很大影响。
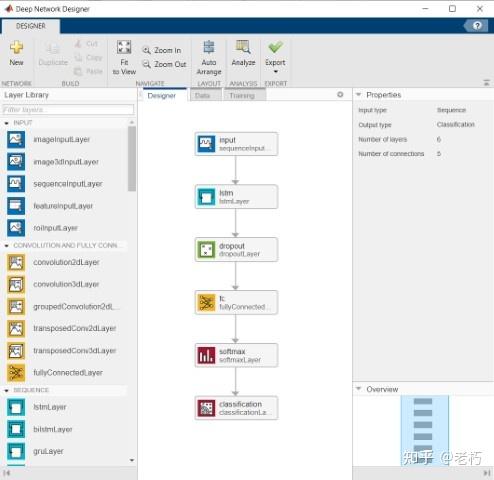
我们使用与问题一相同的方法来比较不同的网络参数,使用Experiment Manager和一个预测引擎剩余使用寿命 (RUL) 的帮助文档示例:
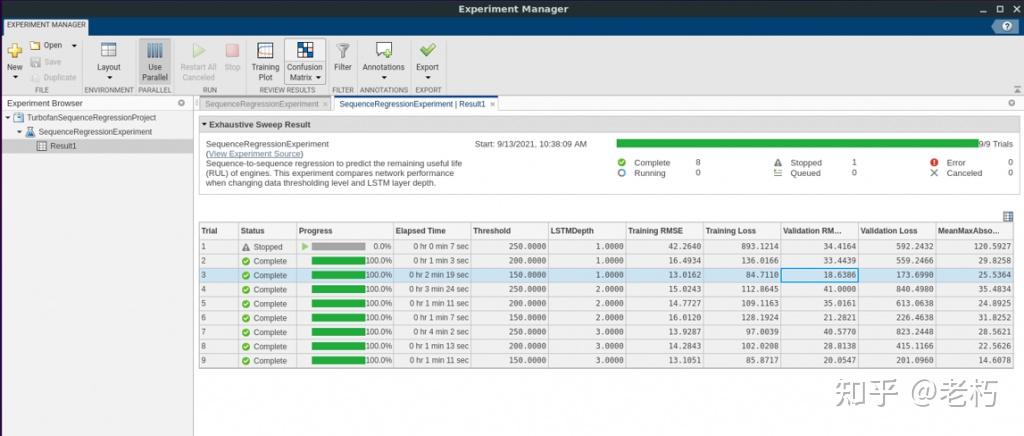
cd(setupExample('nnet/ExperimentManagerSequenceRegressionExample'));setupExpMgr('TurbofanSequenceRegressionProject');我们比较了两个主要的网络参数:阈值 和LSTM 深度。阈值表示响应数据的截止值,LSTMDepth 是层数。
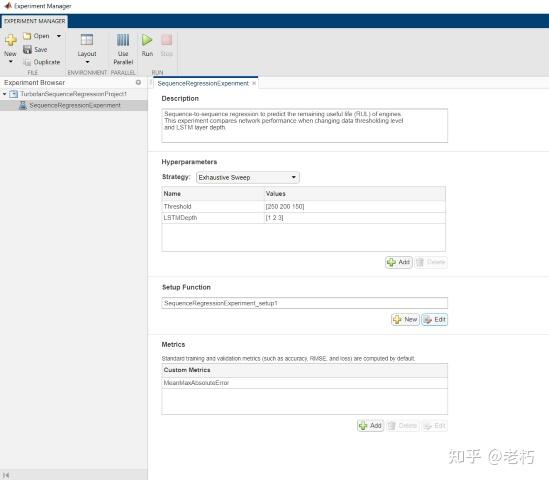
这里用了自定义指标 MeanMaxAbsoluteError,这很有帮助,因为您可以包含任何您喜欢判断拟合优度的方法。我们检查了setup函数,把实验跑起来,然后焦急地等待结果!
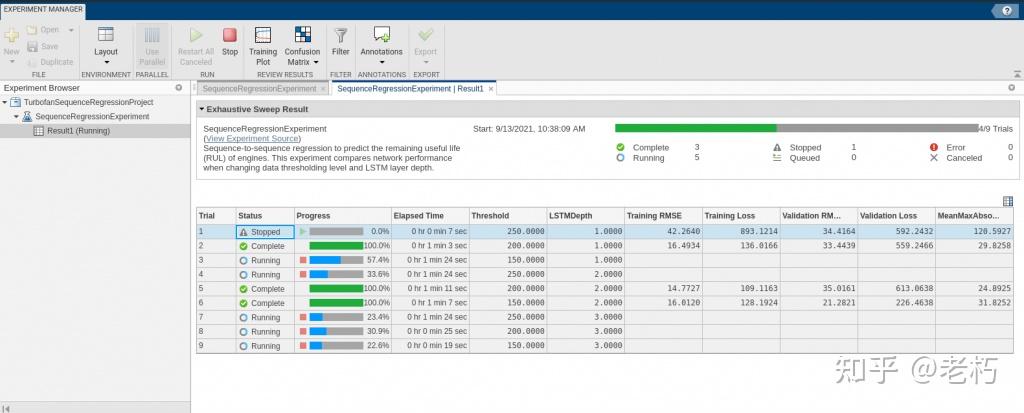
对于预测数值的回归问题,精度的常用度量是已知数据和预测数据之间的 RMSE(均方根误差)。理想情况下,RMSE 尽可能接近于零。
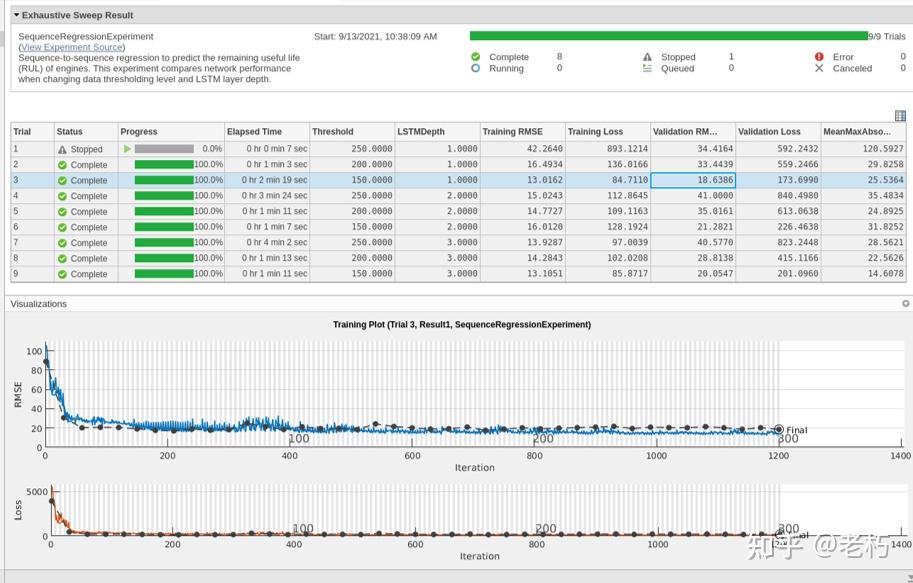
最好的 模型(RMSE最小)是最小阈值(150)和最小深度(1)的网络。在这种情况下,基于网络深度的结果没有任何改进,因此在设置 LSTM 时再次考虑简单性,并将有助于如上所述的可解释性。
文档中有很好的例子,可以更详细地展示 LSTM 训练和评估,包括视频、音频和文本等几个问题。遗憾的是,我们无法在一小时内进行更多比较,但既然我们已经涵盖了基础知识,也许下次我们可以处理更复杂的问题!在此处查看更多示例。
我们能够训练、比较和评估这些漂亮的模型(不到一个小时!)希望这能让您了解如何为您的数据选择网络以及如何设置实验来调整和比较网络。在此过程中,使用APP并仔细考虑评价标准非常有帮助。如果您想了解有关设置自己的实验的更多信息,请访问Joe Hicklin 的这两个视频教程。
我们将再次参加我们的建模竞赛系列 - 订阅@matlab YouTube 频道以继续关注更多信息并在社交媒体和评论中保持联系。让我们知道您接下来想看到什么!
P.S. 本篇为译文,原文在这里:MATLAB's Best Model: Deep Learning Basics
实验|Daylight 算力支持|幻方AIHPC
上一期关于 Alphafold 训练提速的文章讲到,幻方 AI 通过优化数据处理,采用特征预处理和特征裁切两种方式通过降低 CPU 开销,避免数据加载阻塞训练的方式提高了 Alphafold 整体的训练性能。
本期,我们将尝试用另外一种方式,对这个“AI 顶流明星模型”进行二次提速。这次我们的实验思路是用上幻方 AI 的并行训练加速神器之二 hfreduce 以及 hfai.nn 算子加速,它们是否能对 Alphafold 整体的训练进一步加速呢?本期文章将通过实验给出答案。
扫描文末二维码,即可申请试用幻方的AI 训练平台。
之前的文章《幻方萤火 | 模型并行训练工具 hfreduce》提到过,由于幻方 AI 集群的架构特点, Nvidia 官方提供的 NCCL 工具并不能充分发挥萤火二号超算集群的通信带宽,因此幻方 AI 自研了 hfreduce 工具优化显卡间的通信,提高多机多卡的并行训练效率。使用 hfreduce 也只需要简单地将 pytorch DDP 替换为 hfai DDP 即可:
model=hfai.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])对于 Alphafold 模型,其本身的特点是前向传播路径比较长,而反向传播路径较短,具有比较鲜明的“参数规模不大,但计算量大的特点”。我们采用数据并行将数据分散到不同的显卡上进行并行加速,以加快训练效率。因此我们为 Alphafold 的训练引入了 hfreduce,利用 hfai.ddp 工具进行数据并行,尝试进一步推高 Alphafold 在萤火二号超算集群上的计算效率。
然而在实践中我们发现,hfreduce 给 Alphafold 训练带来的训练提升在绝对值上并不大。这是什么原因呢?在随后的实验部分中我们结合实验结果来分析这一问题。
我们设计并进行了三组实验,以对比使用 hfreduce 后的加速效果。实验的设定如下表所示:

我们希望通过多卡和单卡训练的耗时对比,来直接看到多卡通信带来的额外开销。因此,我们对 3 种训练方式测试了其 200 次迭代的平均 backward 耗时。
其中,“特征裁切:最大”代表了对特征进行了尽可能大的裁切,目的是避免因特征处理导致多卡训练时部分 GPU 上的梯度同步长期处于等待状态,影响结果的准确性。使用 hfreduce 时由于梯度同步被单独拆出,因此需要将两个函数合并统计梯度计算+梯度同步的总时间。
此外,训练的基本参数还包括:
根据上文中的实验设定,我们测试 NCCL 并行加速和 hfreduce 并行加速的完整训练结果如下表所示:

直接对比单次迭代的总耗时,从结果来看在 Alphafold 的训练场景下 hfreduce 和 NCCL 的不同选择并不会带来显著的效率差异。理论上来说,hfreduce 比 NCCL 更加适合萤火二号的集群架构,一定能带来比 DDP 更快速的梯度同步。
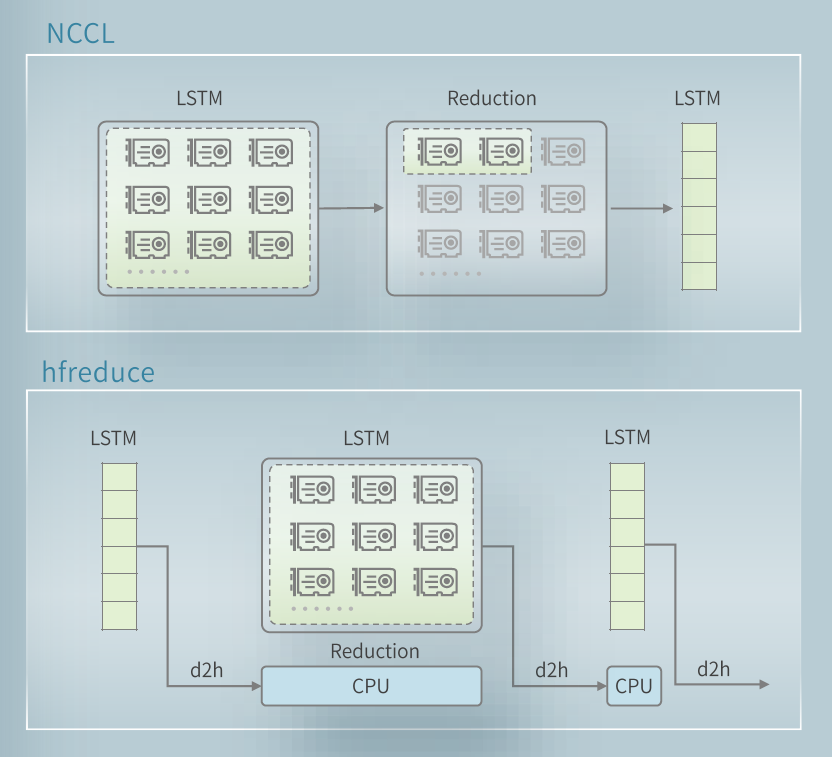
但在 Alphafold 的实验结果中,两次实验中每个 step 的迭代速度几乎完全相同。接下来我们将在理论上对这种实验结果和预期的差异做出一些分析。
对于这种现象,最主要的原因是 Alphafold 独特的模型结构和蛋白质数据的特点使得模型虽然需要很大量的 GPU 运算,却只需要传输很少的梯度数据。Alphafold 的模型参数只有 93.2M,参数量不到 1 亿,使用 FP32 单精度的情况下占用显存 372.8MB。在前向传播时 Alphafold 会将模型中的主要部分(Evoformer)复制 4 次,这会带来一个很长的前向传播通路,使得时间复杂度大大增加。然而,最终模型需要更新的参数依然只有原先的数量,因此显得梯度同步的开销在整个迭代中显得微不足道了。
那么,既然梯度同步的耗时不显著,我们是否可以通过一些 profile 方法拆分出每个部分的耗时,进行定量分析优化呢?我们对 backward 部分进行更细致的测试,最终测试结果如下表所示:
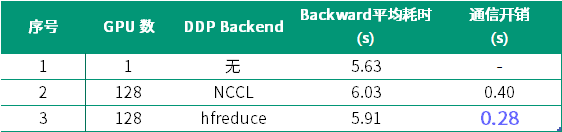
这里,不考虑多卡时因数据处理进度不同产生的等待,那么多卡训练时的 backward 时间减去单卡训练的 backward 时间既可以认为是多机多卡带来的额外通信开销。
上表的结果中可以看到,在萤火二号上使用 DDP 训练时,选择 hfreduce 能够比 NCCL 节省 30% 的通信开销,这是一个非常可观的数字,说明 hfreduce 确实更适合在幻方萤火二号超算平台上进行多机多卡训练的加速。同时,90% 以上的耗时在 forward 的计算上,特别是 LayerNorm 和 Attention 的算子计算开销比较大,这里需要进一步使用 hfai 的优化算子进行进一步提升。
上一期的文章《幻方萤火 | 性能卓越的深度学习算子 hfai.nn》与大家分享了:幻方 AI 针对 Pytorch 框架进行了深度优化,结合萤火二号的集群特点,对一些常用的 AI 算子重新设计研发,进一步提升了模型整体的训练效率。其使用非常简单,只需要在原有的任意模型训练代码中加入一行:
model=hfai.nn.to_hfai(model)hfai 会自动扫描您的代码,替换为优化后的算子。hfai.nn 提供了对当前主流深度学习模型中常用的 MultiHeadAttention,LayerNorm,LSTM 等结构中算子的深度优化,能够大幅加速模型中这些算子的运算。我们尝试在 Alphafold 中引入 hfai.nn 算子库,测试其能够对模型训练产生多大的增益效果。
由于 hfai.nn 的算子加速取决于模型中各类型运算占总 GPU 开销的比重情况,因此我们首先尝试使用 Pyorch Profiler 工具对 Alphafold 模型使用标准 torch 算子时的 GPU 运算时间进行一些分析。在一次总耗时为 12.6s 的迭代中,主要开销情况如下:

仅前 5 类运算占了 Alphafold 训练开销的 70%,而其中 LayerNorm 与 Attention 中的矩阵运算又是最主要的耗时来源:仅 LayerNorm 运算就占了总耗时的 30% 左右。Alphafold 相对一般的 BERT 等 Transformer 类模型更为复杂,使用了自己实现的 Attention,因此在注意力运算上无法获得 hfai.nn 的加速。但同样占据耗时大头的 LayerNorm 却能够使用到 hfai 算子加速,因此可以预期 hfai.nn 能给 alphafold 带来较好的加速效果。
为了探究具体加速效果,我们首先尝试对 Alphafold 中 LayerNorm 的使用情况进行一些分析。一般来说输入 Tensor 的形状往往会对算子加速的效果产生较大的影响,因此在这里我们首先尝试对输入模型中的 LayerNorm 层的不同的 Tensor 形状进行一些理论上的分析。在一个典型 Transformer 类模型中, LayerNorm 的输入形状往往是[BatchSize, SeqLen, EmbDim]。在 Alphafold 中由于其模型结构与简单的 Transformer 模型有较大差异,输入的张量形状会更为特殊一些。模型中 LayerNorm 层的不同 Input Shape 对应的出现频率可见下表:
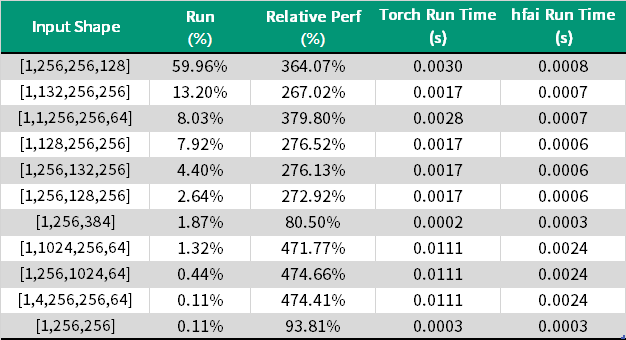
可见在大多数输入时,hfai.nn 提供的 LayerNorm 算子都能取得相比 torch.nn 数倍的大幅性能提升,只在极少数形状下性能可能会稍差于 torch。另外根据上表中不同输入 Tensor 形状的占比可以计算得,使用hfai.nn 在 Alphafold 中可以在 LayerNorm 的 GPU 开销上取得总计 350% 的加速。由于 Alphafold 中的 LayerNorm 使用频率很高,且在模型的不同部分都有使用,因此可以预计对模型整体也能有较明显的加速效果。
在理论分析了 hfai.nn 能给 Alphafold 带来的加速幅度后,我们也希望能了解在实际训练时 Alphafold 能够从 hfai.nn 中获得的收益。因此我们在与 Alphafold 预训练时相同设定的真实场景下使用 128 卡进行了并行训练,分别测试了使用 torch 算子和 hfai 算子进行 Alphafold 训练时的训练耗时情况,结果如下表:

相比于使用 torch.nn 算子进行训练,使用 hfai.nn 时模型整体训练中单次迭代的平均时长能够从 11.26 秒减少到 8.64 秒。可见在 Alphafold 训练时只需要添加一行代码引入 hfai.nn,就足足能够获得 30% 的训练性能提升。值得注意的是,由于 Alphafold 中自定义了 Attention 实现没有使用标准的 nn.MultiHeadAttention,在这里能够获得的 hfai.nn 算子加速效果其实只来自于 LayerNorm 运算减少的耗时。由此可见在常见的标准 Transformer 类模型中,使用 hfai.nn 将更加容易获得大幅的性能提升。
通过上述两个实验,我们验证了 hfreduce 和 hfai.nn 算子对 Alphafold 模型的加速效果。他们分别表现出了不同的加速能力,说明在模型优化的过程中我们需要根据模型的结构特性选择合适的加速方案。这里,幻方 AI 将持续加大研发,提供更多的优化方案和工具。

幻方 AI 团队, 紧跟 AI 研究的前沿浪潮,致力于用领先算力助力 AI 实验落地与价值创造,降低超大算力需求的使用门槛,欢迎各方数据科学家与开发者们一同共建。
扫码申请使用萤火超算
点击下方 幻方AI BLOG 更多干货奉上
幻方 | 技术博客 大模型激活函数稀疏性FFSplit: Split Feed-Forward Network For Optimizing Accuracy-Efficiency Trade-off in Language Model Inference
大模型模型参数太大,既会影响能够同时运行的batch数量,也会影响推理的速度,本文就是为了在尽量保持精度的情况下解决效率问题。
这篇文章是(简称lazy)的延续,

在lazy这篇文章中,我们观察到几个现象:
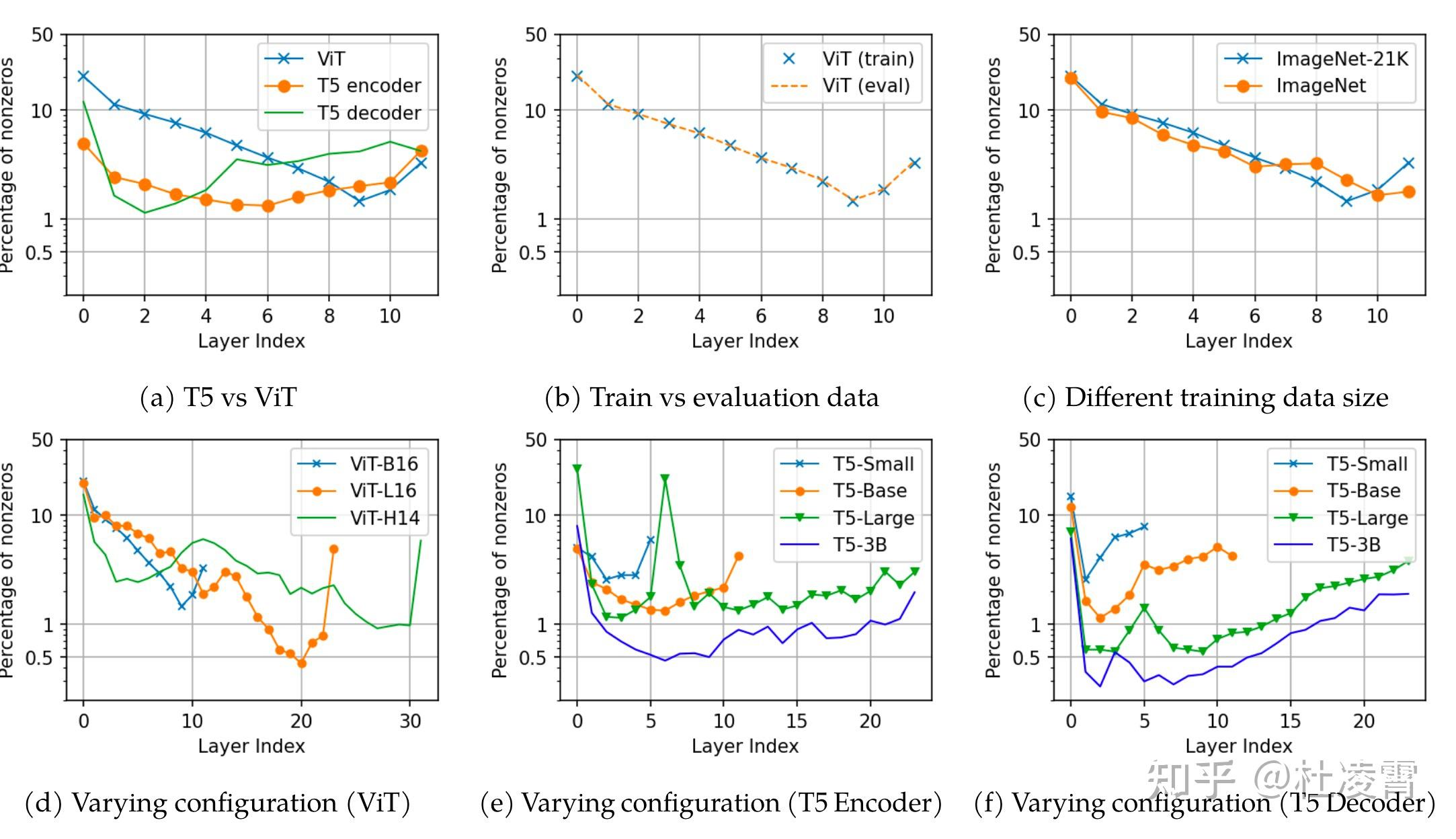
上图是T5和Vit(都是使用ReLU)各层在各种数据上和配置上激活值非0的比例。可以看到,都不到50%是非0的。实际上,训练完之后,encoder-decoder层非0的平均占比是2.7%, 最大的层是12%, 比例最小的层非0激活值占比只有1.1%。
2. 数据无关性
对于所有的数据集,稀疏性是大体一致的。并不是对于不同的数据激活值非0的节点完全不同。
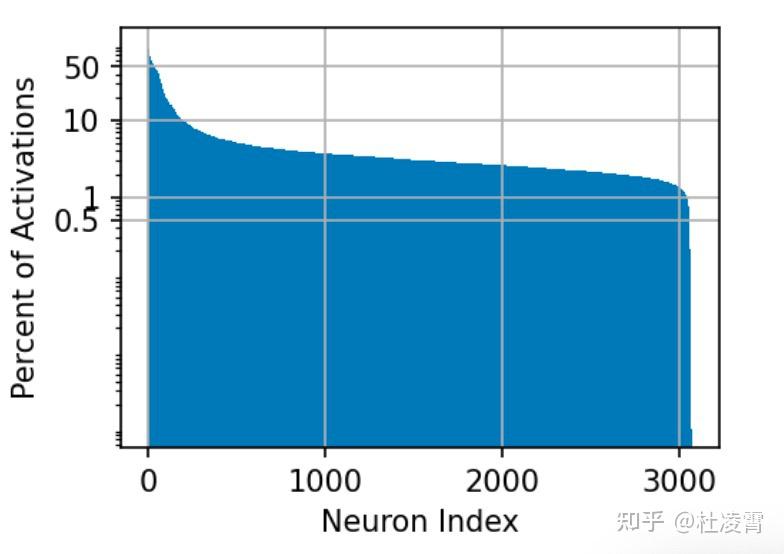
上图是使用C4 dataset在T5的第一层的统计,一部分节点在大约50%的数据经过的时候都会激活;大部分(93.5%左右)在10%的数据经过的时候会被激活。另外,没有一个节点是任何一次都没有被激活的;99%的节点被激活的次数小于1%。
3. 模型越大,稀疏性越强。
本文讨论的目标文章是<FFSplit: Split Feed-Forward Network For Optimizing Accuracy-Efficiency Trade-off in Language Model Inference>

lazy研究针对的激活函数是ReLU, 但是现在主流的大模型使用的激活函数是GeLU或者SwiGLU。FFSplit研究的出发点就是在这些主流大模型使用的激活函数的情况下是否依然有heavy hitter,也就是激活值具有稀疏性,ffn层少量了的神经元经常贡献了绝大部分的值。
GeLU或者SwiGLU不是直接截断,所以研究的范数从ReLU的非零变成了值的大小,从研究非零值的稀疏性变成了研究范数较大值的稀疏性。
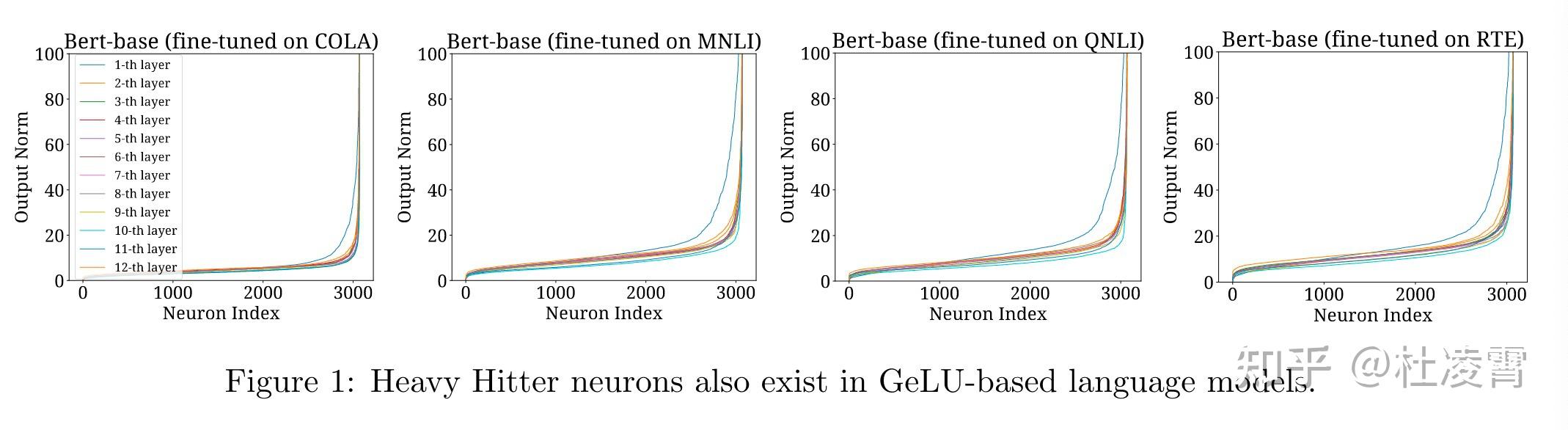
事实上,从上图可以看出,稀疏性依然存在。
那稀疏性有什么作用呢?
直到了那些节点贡献大,哪些小,我们就可以把ffn分成两部分
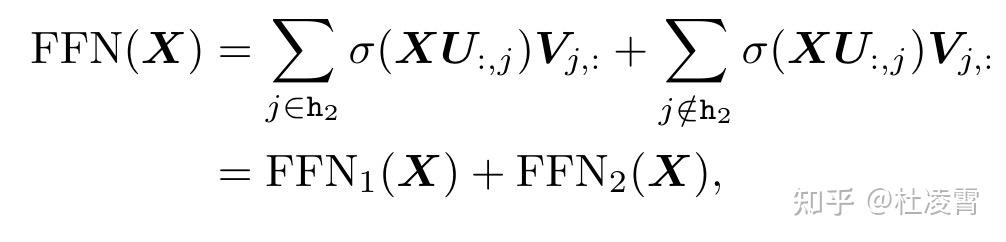
模型太大,我们就对模型进行压缩。为了保证精度,可以对贡献小的那部分压缩得更狠,而对贡献比较大的那部分就分配更多的资源。要知道FFN层的参数占总参数大致。本文实验保持25%的heavy hitter不动,把剩下的75%做svd分解并使用10%的full rank最为最终的rank,把模型压缩了43.1%并且推理速度提升了1.2~1.56倍,结果损失相对较小。
关于华宇娱乐
本站为华宇娱乐,华宇平台永久招商,任何平台的新老会员、代理都可以联系华宇主管申请为总代理、直属,了解详情待遇请加QQ或微信。 客户:为客户提供高质量和最大价值的专业化产品和服务,以真诚和实力赢得客户的理解、尊重和支持。市场:为客户降低采购成本和风险,为客户投资提供切实保障。 发展:追求永续发展的目标,并把它建立在客户满意的基础上。 关于“为合作伙伴创造价值”公司认为客户、供应商、公司股东、公司员工等一切和自...联系我们
电话:400-123-4657
邮箱:admin@youweb.com
地址:广东省广州市天河区88号
传真:+86-123-4567

